Guia de processament Batch (HPC)
Serivdors de computació
Ara que ja estàs preparat, podràs començar a utilitzar els nostres serveis de computació disponibles. Per això, és necessari llegir les Especificacions del grup d'investigació al que pertanys i seguir els passos per connectar-te al teu entorn de desenvolupament (servidor frontend). Una vegada estiguis connectat, entraràs en un servidor anomenat <grup_recerca>Exx.
La pregunta que queda és: Realment on dirigim els nostres experiments?
Si cadascú executa els seus experiments intensius en processament al seu entorn de desenvolupament, això probablement consumiria molta memòria RAM, i aquests servidors (<grup_recerca>Exx) probablement col·lapsarien, o s'executarien massa lentament per programació normal.
Per aquesta raó tenim un servei de computació, per poder executar una gran quantitat d'exeperiments usant tots els nostres servidors de computació, però mantenint els nostres servidors d'accés lliures per ser utilitzats per programar i altres tasques no intensives en processament.
El procés és el següent: Quan envies un treball a un servidor, s'envia a un administrador de cues que busca un node lliure en la teva partició amb la capacitat d'executar un projecte, i quan troba un disponible, executa el teu treball en aquell node, anomenat <grup_recerca>Cxx.
Has de tenir en compte que en aquesta pàgina donem una breu introducció del sistema de monitorització de Gestors de cues, però si es desitja més informació sobre el tema, visita la documentació oficial de slurm.
Pots trobar la llista de nodes disponibles en cada partició de cada grup d'investigació a l'inventari.
Si vols comprovar l'ús dels recursos de treball, si us plau, revisa aquest document.
Monitorització del servei de computació
Per consultar la informació dels recursos del servei de computació i de les particions, pots utilitzar el comandament sinfo:
myuser@mygroupe01:~$ sinfo
Per veure l'estat actual del servei de computació, només cal que teclegis squeue o sview:
myuser@mygroupe01:~$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
240123 standard python asalvado R 2-01:59:39 1 mygroupc5
264825 standard matrix_c etacchin R 2:01:29 1 mygroupc5
En aquest exemple, pots veure que l'usuari asalvado està executant (R) un experiment de python des de fa més de 2 dies, i etacchin un relacionat amb matrius des de fa més de 2 hores, tots dos al node mygroupc5.
Si executes sinfo-usage <nom_particio> podràs veure en detall els recursos disponibles i assignats a qualsevol node de càlcul. Exemple:
myuser@mygroupe01:~$ sinfo-usage gpi.compute
NODE NODE Limit Allocated Available
NAME STATUS CPU GPU RAM CPU GPU RAM CPU GPU RAM
gpic09 mix 32 8 251G 9 2 75G 23 6 176G
gpic10 idle 32 8 251G 0 0 0G 32 8 251G
gpic11 idle 40 8 376G 0 0 0G 40 8 376G
gpic12 mix 40 8 376G 1 1 16G 39 7 360G
gpic13 mix 40 8 251G 8 4 32G 32 4 219G
gpic14 idle 40 6 251G 0 0 0G 40 6 251G
Ara, enviem algun job!
Enviament d'un Job
Coneixes el comandament sleep? Doncs, simplement no fa res durant els segons que especifiquis com a paràmetre... bastant senzill, oi?
Com qualsevol altre comandament, si el tecleges directament a la shell, s'executarà al servidor on estiguis connectat. Si, per exemple, estiguéssim a gpie01(grup de recerca GPI, al servidor de desenvolupament 01):
myuser@gpie01:~$ sleep 10 &
[1] 30329
myuser@gpie01:~$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
240123 standard python asalvado R 2-01:59:49 1 gpic5
264825 standard matrix_c etacchin R 2:01:39 1 gpic5
Recorda que l'& final del comandament sleep 10 & serveix per recuperar el terminal després de la crida i no haver d'esperar que finalitzi (més informació sobre l'execució de comandaments de shell).
Aleshores, després de cridar sleep 10, podem veure que no hi ha hagut cap canvi en el servei de computació... (perquè el comandament sleep s'està executant al servidor de desenvolupament). Però si simplement teclegem srun abans, s'executarà al servei de computació:
myuser@gpie01:~$ srun sleep 10&
[1] 31262
myuser@gpie01:~$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
240123 standard python asalvado R 2-02:00:22 1 gpic5
264825 standard matrix_c etacchin R 2:02:12 1 gpic5
264836 standard sleep myuser R 0:03 1 gpic5
A la darrera línia de la sortida del comandament squeue pots veure que el nostre sleep ara s'està executant, no a gpie01, sinó al node gpic5.
Enviament d'un Job a una cua de partició
El servei de computació es divideix en diverses cues de particions, com en un supermercat. Si, per exemple, pertanyies al Grup de Recerca GPI, les teves possibles particions serien gpi.compute (per a més informació sobre grups de recerca i particions, consulta la pàgina d'Especificacions de Grups de Recerca). En l'exemple del GPI, la partició gpi.compute permet executar el teu comandament amb un límit de temps elevat (24h), però és probable que hagis d'esperar a la cua fins que hi hagi recursos disponibles. Per utilitzar-la:
myuser@gpie01:~$ srun -p gpi.compute sleep 10&
En qualsevol cas, si necessites computar alguna cosa, si us plau, envia-la al sistema i espera que es processi. No cancel·lis els teus propis jobs perquè estiguin esperant. Cancel·lar jobs que realment vols computar és perjudicial per diversos motius:
- Per descomptat, no es computarà fins que el tornis a enviar.
- Com més temps estigui el teu job a la cua, més prioritat guanya per ser el següent a executar-se.
- La longitud de la cua ens permet determinar les necessitats de computació reals del grup, és a dir, les teves necessitats reals de computació.
- Si "esperes" per enviar (sense cap job a la cua) en lloc d'esperar a la cua, per al sistema no estàs esperant realment.
Prioritats d'un Job
La nostra cua gestiona els jobs de manera diferent en funció de la seva ocupació. Si la cua no està plena, funciona com un FIFO (First In, First Out), la qual cosa significa que els servidors assignen els seus recursos basant-se únicament en l'ordre en què els seus clients els han sol·licitat.
No obstant això, quan la cua està plena, passem a utilitzar una prioritat multifactor que gestiona les posicions a la cua basant-se en tres factors: la teva quota (share) (explicada a continuació), la teva ocupació del servidor durant les últimes 24 hores, i el temps que has estat esperant a la cua. El factor més determinant és la quota (fairshare factor).
El procés resumit és el següent:
Tenim tres tipus d'usuaris, i cada tipus té una quota diferent (un percentatge de "propietat" del clúster):
- Members: Doctorands i professors (Quota més alta)
- Collaborators
- Students: Estudiants (Quota més baixa)
L' algoritme fairshare ajusta la prioritat dels jobs per a tots els usuaris per assegurar que tinguin la seva quota corresponent.
Possibles situacions que et pots trobar: Si tens una quota alta però estàs executant molts jobs, la teva prioritat es redueix per permetre que altres passin per davant. D'altra banda, si tens una quota baixa però estàs utilitzant el sistema mínimament, la teva prioritat s'incrementa perquè puguis utilitzar-lo més. A més, com més temps hagis estat esperant a la cua, més alta serà la teva prioritat.
El gestor de cues que utilitzem és Slurm, que és un gestor de càrrega de treball i planificador de jobs de codi obert dissenyat per a clústers de computació d'alt rendiment (HPC) i superordinadors. Pots visitar les pàgines del plugin de prioritat multifactor i de l'algoritme classic fairshare al seu lloc web oficial per obtenir informació més detallada sobre aquest tema.
Cancel·lació d'un Job
Per cancel·lar un job que està en execució, has d'obtenir la seva jobid executant squeue, i llavors només cal que facis:
>> scancel $JOBID
On $JOBID és l'identificador del teu job en execució. El pots veure a les primeres línies quan el teu job comença, o a la sortida del comandament squeue.
Sol·licitud de Recursos de Computació
CPUs
Per sol·licitar 2 CPUs:
>> srun -c 2 ./myapp
RAM
Per sol·licitar 4 GB de RAM:
>> srun --mem 4G ./myapp
Si reps el missatge srun: error: task: Killed, és probable que la teva aplicació estigui utilitzant més RAM de la que has reservat. Simplement, sol·licita més RAM, o intenta reduir la quantitat de RAM que necessites.
GPUs i la seva RAM
Les GPUs formen part dels Recursos Genèrics (gres), així que per sol·licitar 1 GPU:
>> srun --gres=gpu:1 ./myapp
Si vols una GPU amb almenys 6 GB de RAM:
>> srun --gres=gpu:1,gpumem:6G ./myapp
Normalment, necessites comprovar quanta RAM de GPU està utilitzant el teu job. El comandament nvidia-smi és el correcte per utilitzar, però per integrar-lo al nostre servei de computació, hauries d'utilitzar:
>> srun-monitor-gpu $JOBID
Recorda que sempre has d'especificar el paràmetre -A quan utilitzis el comandament srun per evitar missatges d'error, i ha de ser el grup al qual pertany la teva partició. Tots els nostres comptes tenen els mateixos noms que els nostres grups de recerca; per exemple, si ets del grup de recerca CSL, hauries d'utilitzar el paràmetre -A csl, i llavors especificar una de les nostres dues possibles particions a CSL (csl i csl.develop) amb el paràmetre -p.
Recorda que sempre pots teclejar el comandament srun -h per obtenir més informació sobre les seves opcions.
Interfícies Gràfiques
Si el teu job realitza algun tipus de visualització gràfica (obre qualsevol finestra), llavors necessites passar un paràmetre extra --x11:
>> srun --x11 ./myapp
Enviar Jobs amb un Fitxer Batch
També pots crear un script automatitzat. En aquest cas, demanes una GPU. Mira aquest exemple, myscript.sh:
#!/bin/bash
#SBATCH -p veu # Partition to submit to
#SBATCH --mem=1G # Max CPU Memory
#SBATCH --gres=gpu:1
python myprogram.py
>> sbatch myscript.sh
Jobs Interactius
Si, per exemple, pertanys al grup de recerca GPI i estàs treballant actualment a l'entorn de desenvolupament gpie01, t'hauries d'adonar que gpie01 té limitacions de CPU i memòria per usuari. Això significa que algunes operacions diàries podrien anar lentes o fins i tot ser "aturades". Quan això passi, hauries de treballar amb una shell interactiva executada dins d'un job. Totes les operacions s'executaran en un servidor de càlcul, però al mateix temps, s'aplicaran al teu directori actual. Aquí teniu un exemple:
>> srun --pty --mem 16000 -c2 --time 2:00:00 /bin/bash
Aleshores, podràs executar de manera interactiva el que vulguis, disposant de 2 nuclis de CPU i 16GB de RAM en un servidor de càlcul remot durant 2 hores.
Tingues en compte que aquesta explicació s'aplica a tots els entorns de desenvolupament de qualsevol grup de recerca; gpie01 és només un cas d'exemple.
Job Arrays
Si tenim previst executar el mateix experiment centenars o milers de vegades, canviant només alguns paràmetres, els Job Arrays són el nostre aliat.
La millor manera d'entendre'ls és seguint un exemple.
Imagina que volem executar aquests tres comandaments:
>> srun myapp --param 10
>> srun myapp --param 15
>> srun myapp --param 20
En aquest cas d'ús senzill, podríem fer-ho així: tres comandaments srun.
Però si volem provar myapp amb centenars o milers de paràmetres, fer-ho manualment no és una opció; i els job arrays estan aquí per al rescat!
Per aconseguir aquests tres comandaments utilitzant Job Arrays, sempre necessitem crear un script de shell que podem anomenar worker.sh. Una primera aproximació per resoldre el problema podria ser un worker.sh com aquest:
#!/bin/bash
myapp --param $SLURM_ARRAY_TASK_ID
I l'hauríem de llançar amb:
>> sbatch --array=10,15,20 worker.sh
Aquí hem de tenir en compte diverses coses:
- El comandament sbatch és gairebé com srun, però per a scripts de shell.
- L'script worker.sh s'executa amb srun totes les vegades sol·licitades al paràmetre --array del comandament sbatch.
- Els valors i rangs passats a --array es converteixen a la variable $SLURM_ARRAY_TASK_ID en cada execució.
- Per defecte, la sortida estàndard i l'error es guarden en fitxers amb noms com ara slurm-jobid-taskid.out al directori actual.
Per exemple, provem el nostre primer "hello job array" amb un worker senzill que només imprimeix un missatge "hello world" i espera una mica per conveniència:
imatge@nx2:~>> cat worker.sh
#!/bin/bash
echo "Hello job array with parameter: " $SLURM_ARRAY_TASK_ID
sleep 10 # to be able to run squeue
Podem llançar 5 jobs en un array amb:
>> sbatch --array=0-5 worker.sh
Submitted batch job 43702
Si monitorem la cua, veiem les nostres 5 execucions:
>> squeue
JOBID PARTITION NAME USER ST TIME CPUS MIN_MEM GRES NODELIST(REASON)
43702_0 standard worker.sh imatge R 0:02 1 256M (null) v5
43702_1 standard worker.sh imatge R 0:02 1 256M (null) c4
43702_2 standard worker.sh imatge R 0:02 1 256M (null) c4
43702_3 standard worker.sh imatge R 0:02 1 256M (null) c4
43702_4 standard worker.sh imatge R 0:02 1 256M (null) c4
43702_5 standard worker.sh
Un cop finalitzats, podem veure els fitxers de sortida al directori actual seguint els noms slurm-jobid-taskid:
>> ll slurm-43702_*
-rw-r--r-- 1 imatge imatge 35 Nov 4 19:21 slurm-43702_0.out
-rw-r--r-- 1 imatge imatge 35 Nov 4 19:20 slurm-43702_1.out
-rw-r--r-- 1 imatge imatge 35 Nov 4 19:20 slurm-43702_2.out
-rw-r--r-- 1 imatge imatge 35 Nov 4 19:20 slurm-43702_3.out
-rw-r--r-- 1 imatge imatge 35 Nov 4 19:20 slurm-43702_4.out
-rw-r--r-- 1 imatge imatge 35 Nov 4 19:20 slurm-43702_5.out
I podem comprovar el contingut de sortida esperat:
>> cat slurm-43702_*
Hello job array with parameter: 0
Hello job array with parameter: 1
Hello job array with parameter: 2
Hello job array with parameter: 3
Hello job array with parameter: 4
Hello job array with parameter: 5
Tingues en compte que pots combinar rangs i valors al paràmetre --array del comandament sbatch d'aquesta manera:
>> sbatch --array=1-3,5-7,100 worker.sh
Submitted batch job 43710
>> cat slurm-43710_*
Hello job array with parameter: 100
Hello job array with parameter: 1
Hello job array with parameter: 2
Hello job array with parameter: 3
Hello job array with parameter: 5
Hello job array with parameter: 6
Hello job array with parameter: 7
Aquesta flexibilitat en rangs i valors pot ser molt útil quan, per exemple, executem milers de workers, però només alguns han fallat i volem tornar a executar només aquests.
Tingues en compte també que podem utilitzar un script de Python (o qualsevol altre llenguatge de scripting) com a worker, així:
>> cat worker.py
#!/usr/bin/python
import os
print "Hello job array with Python, parameter: ", os.environ['SLURM_ARRAY_TASK_ID']
>> sbatch --array=1-3 worker.py
Submitted batch job 43720
>> cat slurm-43720_*
Hello job array with Python, parameter: 1
Hello job array with Python, parameter: 2
Hello job array with Python, parameter: 3
Podem utilitzar arrays o diccionaris al nostre script per gestionar múltiples paràmetres del nostre script worker:
>> cat worker.sh
#!/bin/bash
param1[0]="Bob"; param2[0]="Monday"
param1[1]="Sam"; param2[1]="Monday"
param1[2]="Bob"; param2[2]="Tuesday"
param1[3]="Sam"; param2[3]="Tuesday"
echo "My friend" ${param1[$SLURM_ARRAY_TASK_ID]} "will come on" ${param2[$SLURM_ARRAY_TASK_ID]}
>> sbatch --array=0-3 worker.sh
Submitted batch job 43734
>> cat slurm-43734_*
My friend Bob will come on Monday
My friend Sam will come on Monday
My friend Bob will come on Tuesday
My friend Sam will come on Tuesday
Per gestionar paràmetres, també podem utilitzar fitxers externs i usar la variable SLURM_ARRAY_TASK_ID com a número de línia per llegir els paràmetres desitjats, així:
>> cat param1.txt
Bob
Sam
Bob
Sam
>> cat param2.txt
Monday
Monday
Tuesday
Tuesday
>> cat worker.sh
#!/bin/bash
param1=`sed "${SLURM_ARRAY_TASK_ID}q;d" param1.txt`
param2=`sed "${SLURM_ARRAY_TASK_ID}q;d" param2.txt`
echo "My friend" $param1 "will come on" $param2
>> sbatch --array=1-4 worker.sh
Submitted batch job 43740
>> cat slurm-43740_*
My friend Bob will come on Monday
My friend Sam will come on Monday
My friend Bob will come on Tuesday
My friend Sam will come on Tuesday
Tingues en compte que en aquest cas hem d'utilitzar el rang 1 - 4 en lloc del rang 0 - 3 que vam utilitzar quan vam guardar els paràmetres en arrays en lloc de fitxers.
Computació amb Suport d'Interfície Gràfica d'Usuari
Aquest servei es basa en el programari de codi obert anomenat Open OnDemand. La pàgina web d'accés és https://ondemand.tsc.upc.edu/ i pots iniciar sessió amb el teu nom d'usuari i contrasenya de la UPC.
La imatge següent mostra les dreceres de l'entorn:

- A "File" (Fitxer) podràs explorar els fitxers que es troben al teu directori home. També hi ha un editor de fitxers bàsic.
- A "Interactive Apps" (Aplicacions Interactives) o a la icona corresponent, se't mostraran les aplicacions disponibles per al teu usuari. Depenent del teu grup de recerca, hi trobaràs la teva "Desktop APP" (Aplicació d'Escriptori) relacionada.
Un cop facis clic a la teva Aplicació d'Escriptori, trobaràs un formulari com aquest:
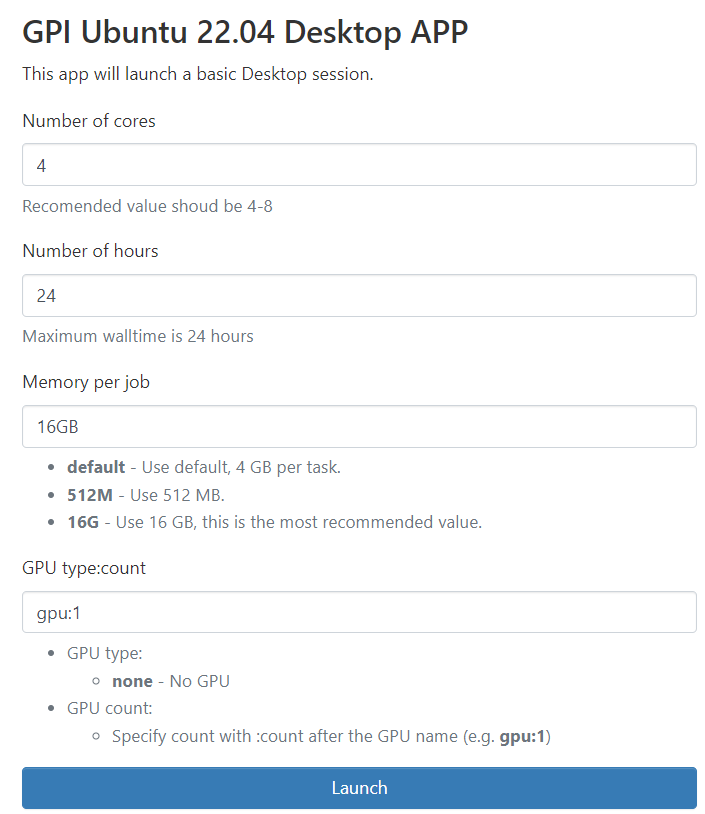
Aquí pots configurar un job de la mateixa manera que ho fas amb el comandament srun. Així, pots triar el nombre de nuclis de CPU, la memòria RAM i, opcionalment, un nombre de GPUs.
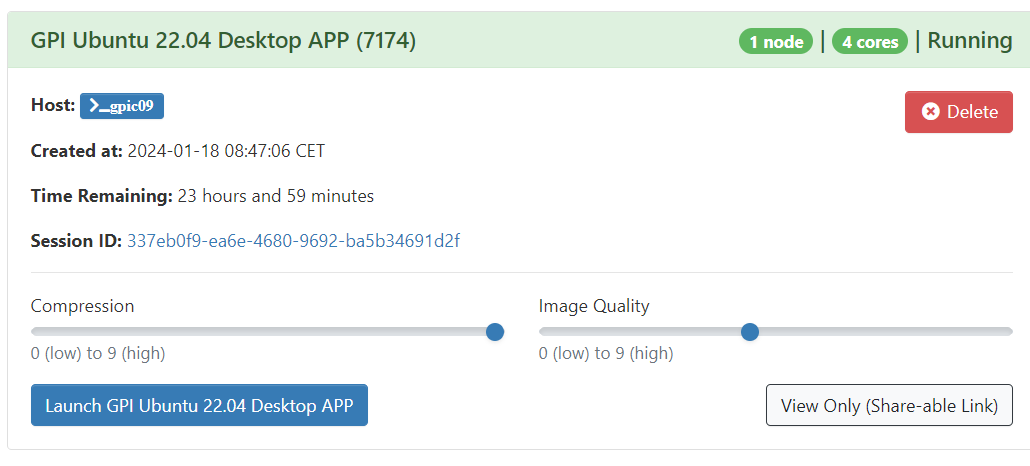
Un cop configurat i facis clic a "Launch" (Llançar), s'obrirà un escriptori en un dels nostres servidors de càlcul. Veuràs que estarà a "queued" (en cua) durant un temps. Un cop canviï a "Running" (en execució), puja la "Image Quality" (Qualitat de la imatge) al màxim i podràs accedir al teu escriptori.
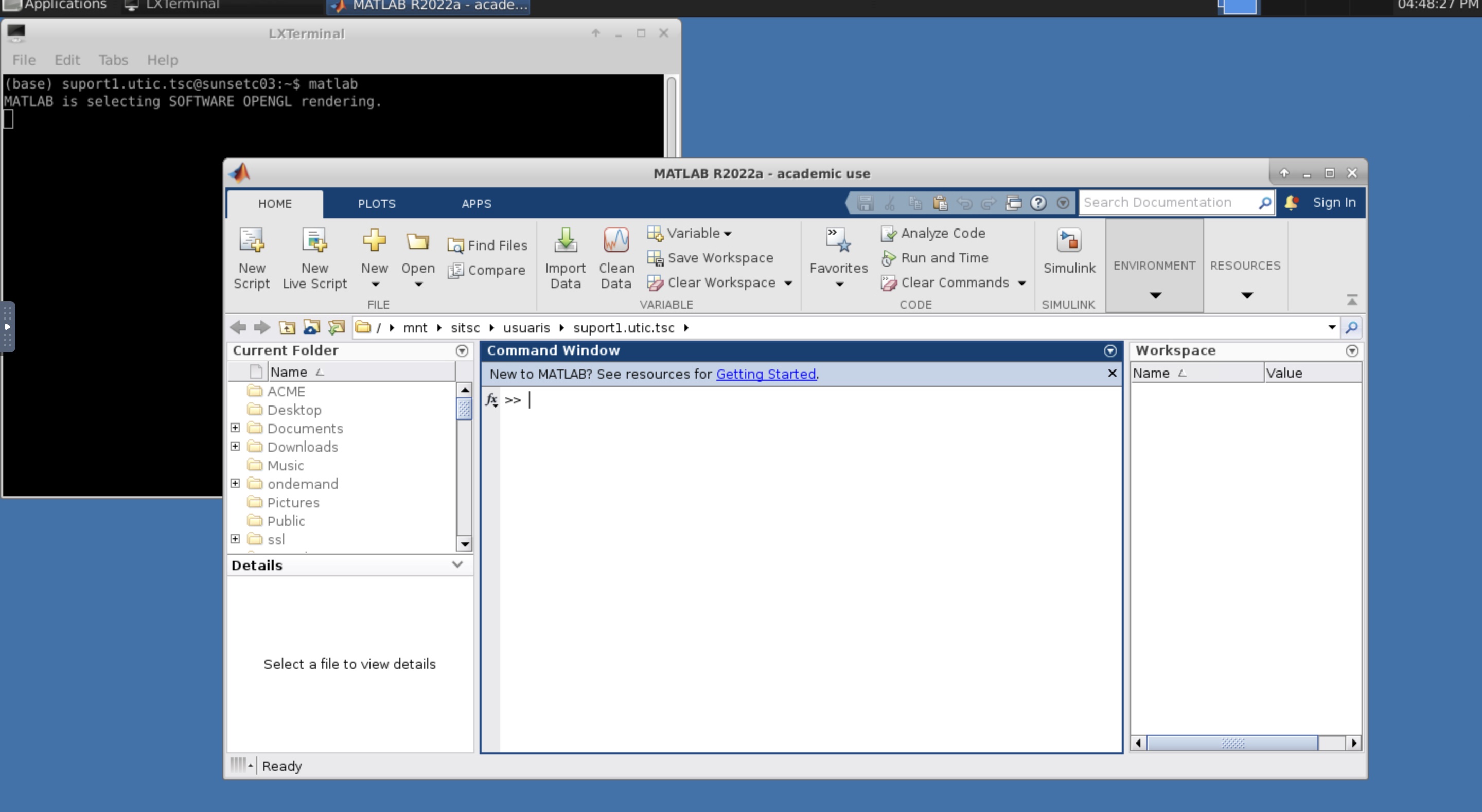
Quan s'obri, veuràs un terminal (una finestra negra amb el teu nom d'usuari). No la tanquis o finalitzaràs la sessió. En aquest terminal pots obrir qualsevol programari instal·lat a "Calcula". A la figura d'exemple s'està executant una aplicació de Matlab.
Quan hagis acabat d'utilitzar el teu escriptori, pots finalitzar la sessió fent clic a "Delete" (Esborrar). Tancar el navegador web no finalitza la sessió en execució, així que pots reprendre la teva connexió remota en qualsevol moment abans que el job deixi d'executar-se.
Comparteix: